





{{!completeInfo?'请完善个人信息':''}}
扬帆创投微信小程序
更聚焦的出海投融资平台
精准高效领先的融资对接服务
精准高效领先的融资对接服务

微信扫一扫进入小程序

伴随着 Sora 的出现,国内的 AI 企业呢?有无类似 Sora 的产品?有无相应的技术积累?有无快速组建团队跟进文生视频技术的能力?

2024 年 2 月 16 日。
就在谷歌发布他新一代的多模态大模型 Gemini 1.5 Pro 的同一天,OpenAI 带着新一代的文生视频模型 Sora 再次抓住了全世界人们的眼球。
“颠覆”、“炸裂”、“变天”、“疯狂”,类似的形容词一夜之间簇拥在 Sora 周围,可能不同于 ChatGPT,我们还需要与其“促膝长谈”才能惊觉它的与众不同,Sora 几乎是以一种所见即所得的方法将震撼输入到我们的眼眶。
如果说从文本到文本的一问一答,从输入到输出模型为我们提供与增加的信息量我们尚且可以想象的话,Sora 这样从文本到视频的输入输出可能只有用“创造”一词可以概括。
而同时,已经被 ChatGPT 的成功培养过的 AI 创业者投资者们马上看到了隐藏在这意为“天空”的四个字母组合下巨大的商业机遇,风口之下,转回自身,我们可能马上会想到:“伴随着 Sora 的出现,国内的 AI 企业呢?有无类似 Sora 的产品?有无相应的技术积累?有无快速组建团队跟进文生视频技术的能力?”

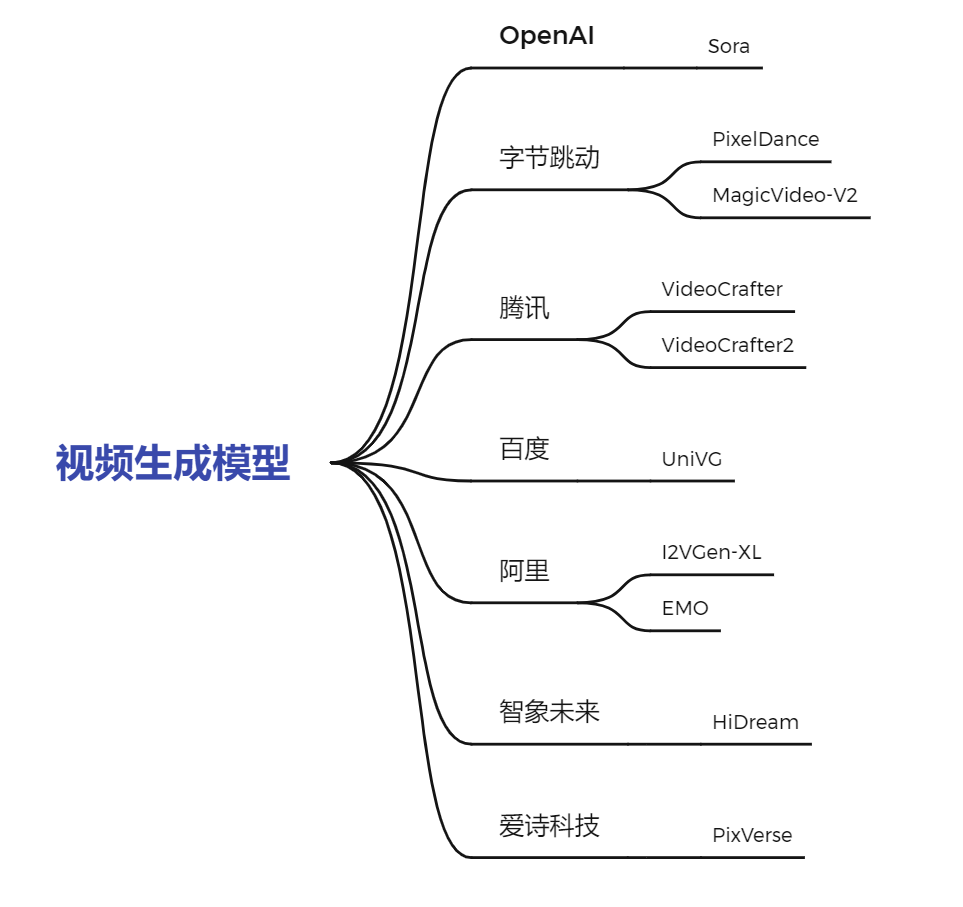
那么今天,我们就对国内视频生成模型的现状来一次“工业大摸底”,看看当下国内的视频生成模型究竟如何到底怎样,与 Sora 差距几何又有无亮眼之处。我们整体介绍了国内包含字节、腾讯、百度、阿里以及两家创业企业的 9 个视频生成模型,整体汇总如下:
OK,在介绍国产模型之前,让我们先从 Sora 开始讲起……
OpenAI:Sora
事实上,就像大语言模型,文生视频并不是一个 OpenAI “独创”的领域,而是伴随着如文生图技术的进步与发展衍生出的,具有更高技术难度与复杂度的“子领域”。在 Sora 之前,我们就已经报道过不少关于文生视频的工作,简单列举几个譬如:
· 谷歌重磅发布零样本视频生成模型!效果惊艳,赶超扩散模型?
· 字节最新文生视频模型,引发围观!狐狸跳舞超丝滑,效果超Gen-2
· 短视频界的变革者:上海 AI lab 发布 Vlogger,几句话生成分钟级视频
· AI自导自演的电视剧,每个角色都是一个大模型,斯坦福25人小镇精神续作
· ……
可以看到,在视频生成领域,很早就有 Pika、Runway、Gen-2 等等珠玉在前,那么面对这么多视频生成的工作,为什么只有 Sora 成功破圈了呢?
面对这个问题,就让我们首先来快速过一下 Sora 的技术报告,文章题为《Video generation models as world simulators》,在开篇伊始,OpenAI 强调的反而不是其卓越的视频生成能力,而是其作为“世界模拟器”的潜力。
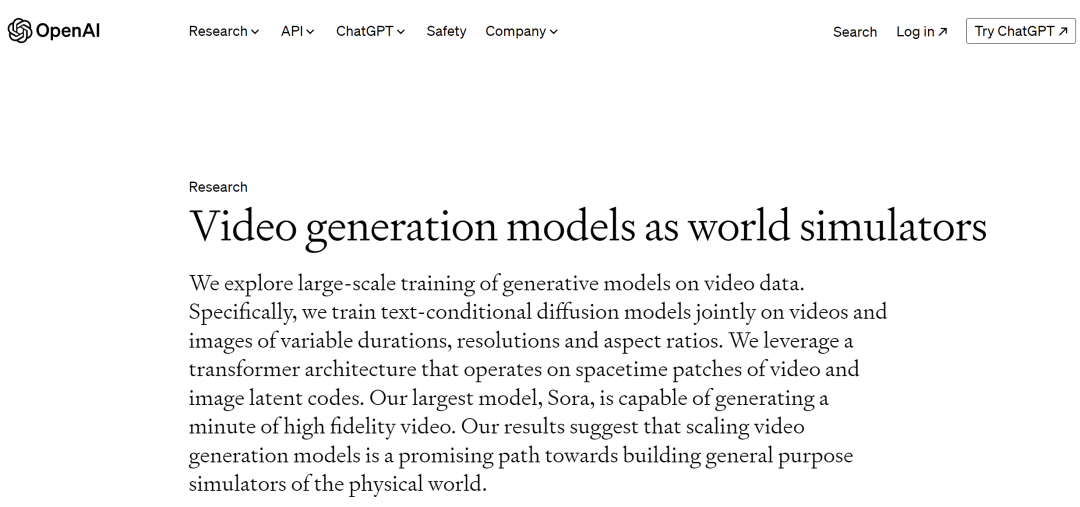
这里其实划重点,区别于以往的视频生成工作,Sora 在生成高清精美的视频背后,事实上为 AGI 探索了一条“模拟真实世界模型”的技术进路,Sora 生成的视频惊人的展现了模型对“物理世界”这个抽象概念的理解,复述英伟达人工智能研究院 Jim Fan 的评论:“如果你还是把Sora当做DALLE那样的生成式玩具,还是好好想想吧,这是一个数据驱动的物理引擎。”
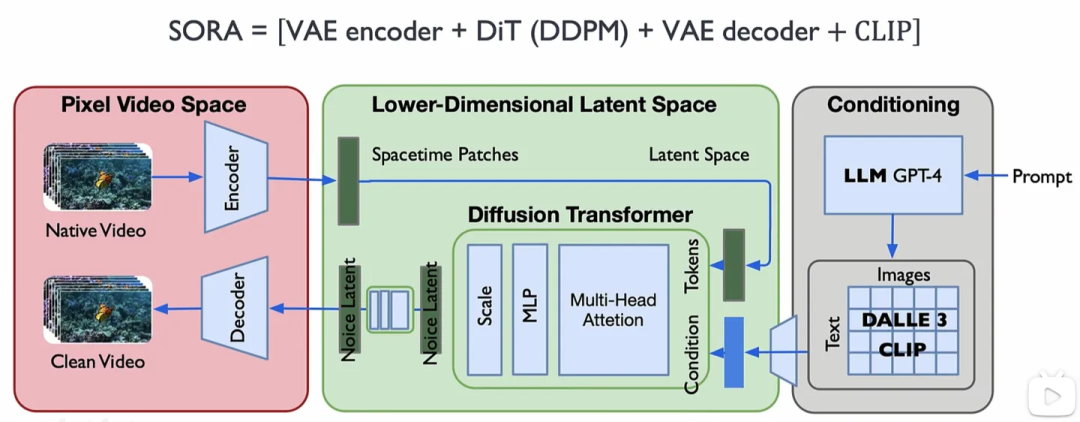
从技术架构的角度,目前大部分学者仍然是认为 Sora 展现的 World Simulators 功能仍然是很有 OpenAI 风格的参数量增加导致的“涌现”的结果。其实先不说是大模型,哪怕是最先进的仿真软件在建模物理世界这件事上都面临着极大的困难,从视频生成的角度,模型理解物理世界需要做到比如三维一致性,物体持久性,长距离连贯性等等,而这一切是如何从目前技术报告中公布的 VAE编码器 + ViT + 条件扩散 + DiT模块 + VAE解码器中得到似乎还是一个未解之谜。
而除了充满科幻色彩的“世界模拟器”,作为一个“文生视频大模型”,Sora 最突出也是最令人震撼的一点在于,它可以根据 Prompt 文字直接生成 60 秒的连贯视频,60 秒看似不长,但是在 Sora 出现以前,AI 生成视频的平均长度仅仅在 4 秒左右,而如果再给这个数字一个参照物,人均单日使用时长超 2.5 小时的抖音短视频的平均长度仅仅在 20-30 秒之间,对于商业电影,60 秒意味着 15 个镜头,对于优秀导演而言甚至足够叙述一个完整的故事。
此外,在视频时长这个可以被量化对比的指标以外,Sora 给人更直观的感受是其绝佳的“连贯性”,
不是面向阅读论文关注量化指标的审稿人而是面向大众,高清连贯的视频更能给人带来以最为直观的视觉冲击。
同时,Sora 的“逼真度”也着将视频生成上升到了一个新的高度,如下图所示,如果不是央视特殊标注“模型生成视频”,有几个人可以从这个眼睛中看到一丝破绽?

而除了这些最直观的颠覆以外,Sora 还带来了诸如更强的语义理解能力、对不同宽高比和分辨率的适应能力、优秀的视频扩展能力等等,也无怪于 Sora 横空出世就可以为视频生成带来“ChatGPT 时刻”。
OK,先入为主看完 Sora 实现的神奇功能,那么再让我们站在更高的视角带着批判的眼光看看过去半年内国产视频生成模型现状!
字节:MagicVideo-V2/PixelDance
在国内大厂中,视频生成领域布局最多的还是当属靠短视频发家致富的字节跳动,事实上在 Sora 面世前的一个月,字节其实刚刚推出了一款文生视频模型 MagicVideo-V2,通过将文生图像、图像生成视频、视频到视频和视频帧插值四大模型集成在一个框架内,使得 MagicVideo-V2 有能力生成高清、流畅与连贯的视频。
在论文中字节强调这是一款在视频高清度、润滑度、连贯性、文本语义还原等方面击败主流的如 Runway, Pika 1.0, Morph, Moon Valley and Stable Video Diffusion 等的先进文生视频模型
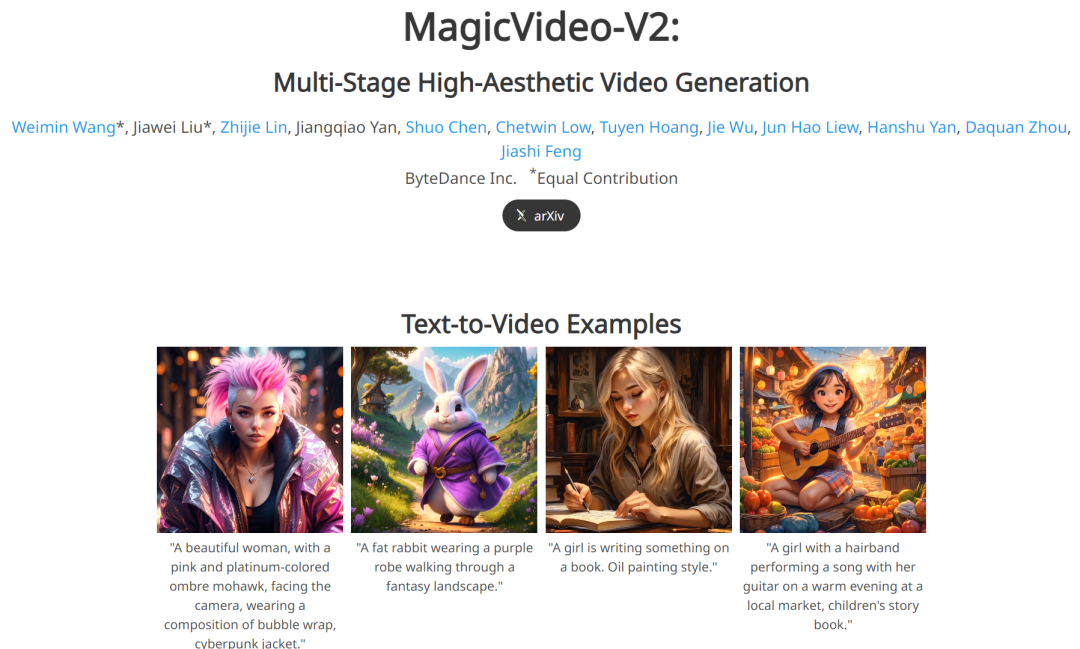
从官网(https://magicvideov2.github.io)的例子中来看,视频的清晰度、逼真程度与动作的连贯性其实都相当不错,举例来看,让 MagicVideo-V2 生成一只弹吉他的北极熊,视频高清度、文本语义还原程度与连贯性都相当不错

而再如希望生成不是卡通而是更加真实一点的视频,一个小男孩在公园小路上骑自行车,这里我们可以看到对比 Sora “以假乱真” 式的结果,MagicVideo-V2 则略显“卡通”,仍然有不真实的感觉存在,并且一些细节部位的处理的仍然不到位:

当然,前面说的不够逼真与略显卡通事实都无伤大雅,对比 Sora 真正让 MagicVideo-V2 一败涂地的还是视频时长,从上面的例子中也可以看出,MagicVideo-V2 生成的视频时长仍然在 3-4 秒之内,我们往往只能看到“图片”确实动起来了,但远没有 Sora 带给我们大片式的震撼。
除了最新的 MagicVideo-V2,去年 11 月字节也发布了一款文字 + 首帧指导(图片)+ 尾帧指导(图片)生成视频的工具 PixelDance。

区别于完全的文本到视频的转换,PixelDance 的模式是从指导图片+文本描述到视频的转换,尽管也是 GIF 画风,但是清晰度与流畅度已经可以让人眼前一亮,比如下面这段“铜雕夫妻接吻并旋转”

但是视频整体风格仍然有点“虚假”,认人物动作有时候也比较僵硬,比如下面这个“女孩慢慢转过头,微笑,头发”:

而除却上面这些三四秒的动画,也许是得益于有“图片”信息的辅助,在官网(https://makepixelsdance.github.io)中,PixelDance 令人惊喜的制造了一部“超越” Sora 的三分钟微电影:
不过从上面这部“电影”来看,动作不自然、转场僵硬,角色突然的形变等等这类问题数不胜数,还远远未达到“颠覆短视频业”的程度。
而其实事实上在去年 11 月 PixelDance 面世之初,也就是三四个月前,视频生成业界的观点还停留在:“生成有高度一致性且有丰富动态性的视频,让视频内容真正地动起来,是目前视频生成领域中的最大挑战”。而对比当时的观点与这些“旧模型”,Sora 带给人们的震撼可能也并不难以理解。
除了 MagicVideo-V2 与 PixelDance 以外,这两天抖音旗下的剪映也宣布文生图工具 Dreamina 即将上线文生视频的功能,并且正在内测,当下 Sora 热度未减,不知道 Dreamina 能否带给大家不同于 MagicVideo-V2 的惊喜,让我们一起期待。
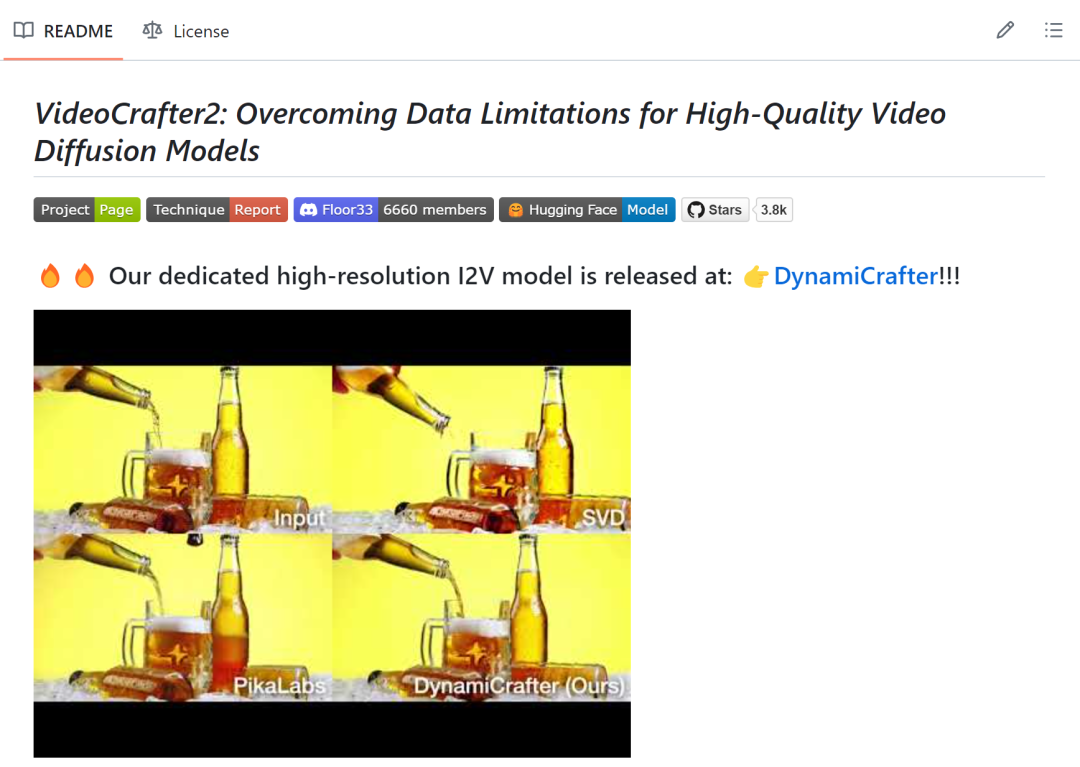
腾讯:VideoCrafter2
非常有意思的是,在字节发布 MagicVideo-V2 仅仅一天后(1 月 17 日),国内大厂像玩起萝卜蹲式的推出自己的视频生成模型,前有腾讯的 VideoCrafter2,后有百度的 UniVG,先来说说腾讯的 VideoCrafter2。
顾名思义,VideoCrafter2 是与 PixelDance 同期发布的 VideoCrafter 的续作,先来简单看看这个 VideoCrafter 的“成片”,比如“宇航员骑马”:

效果其实与同期的几个模型大同小异,不过 VideoCrafter 在个性化视频生成与视频生成控制上做了文章,支持在一组特定的视频片段或图像中对模型进行微调以迁移视频风格与更深度的控制生成结果的能力。
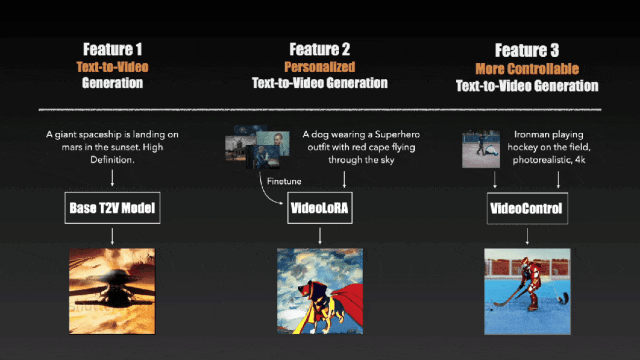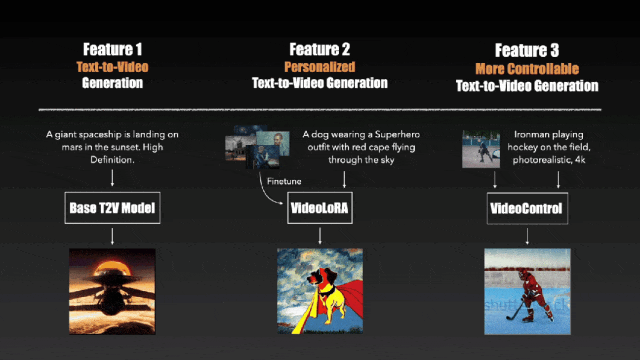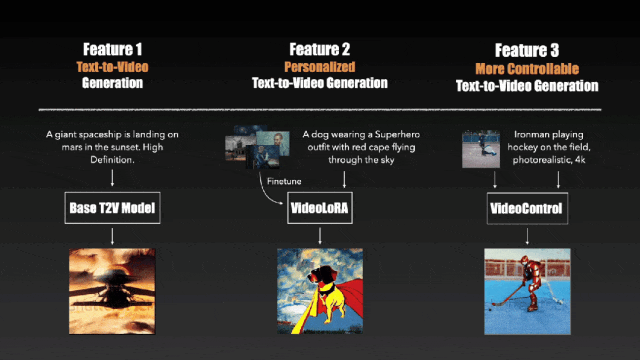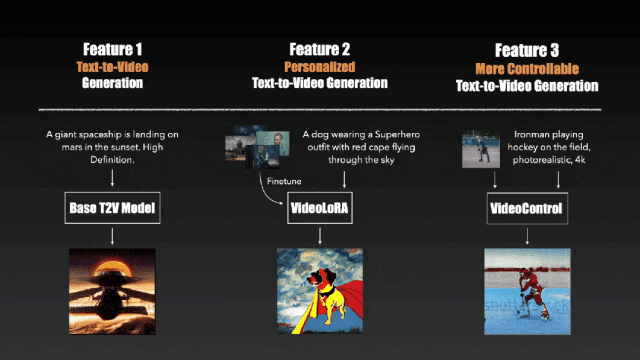
值得注意的是,VideoCrafter 使用的是被 Sora 用Diffusion Transformer(DiT)“扬弃” 了的 U-net 网络,而这一点在 VideoCrafter2 中也没有改变。而事实上,VideoCrafter2 的主要贡献集中在了“如何用低质量视频和高质量图像数据生成高质量视频”上(https://github.com/AILab-CVC/VideoCrafter)。
当然,对比原始的 VideoCrafter,VideoCrafter2 在视频清晰度与动态效果上也有极大的提升,比如“一个孩子兴奋地在有点生锈的秋千上荡秋千”
再如:“一位戴眼镜的年轻女子戴着粉红色的头带在公园慢跑”

整体来看视频的清晰度,流畅程度其实都可圈可点,这种在低质量数据中训练高质量视频的方法也非常有可取之处。不过遗憾的是,如果我们先入为主首先看过了 Sora 生成的视频,无论是从视频长度、动作质量,还是人物形变等等方面,总会令人感觉这二者仿佛不在一个维度进行竞争。
百度:UniVG
说完了腾讯的 VideoCrafter2,再来看看百度同天上线的 UniVG(https://univg-baidu.github.io),区别于腾讯主要在从低质量数据到高质量数据上做文章,百度 UniVG 的卖点主要在于“Unified-Model”,期望构建一种文字与图片任意组合输入的更加灵活的视频生成模型。

从生成结果来看,UniVG 的清晰度非常令人惊喜,比如“一只猫正在吃胡萝卜”

“小女孩与鱼”
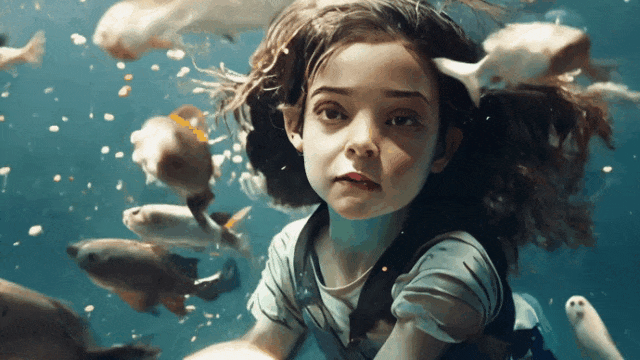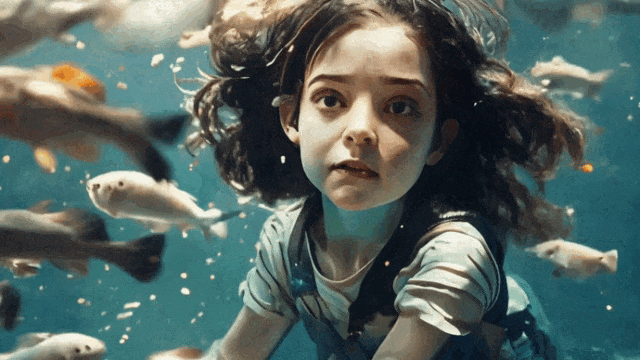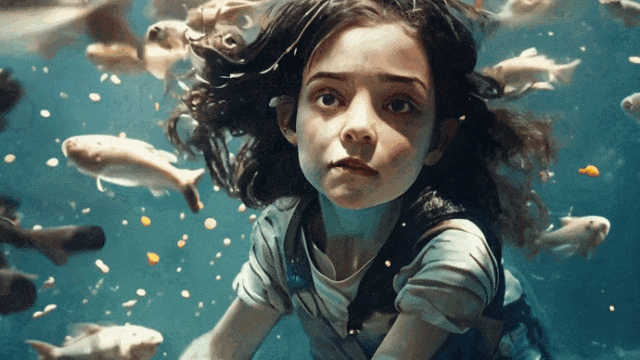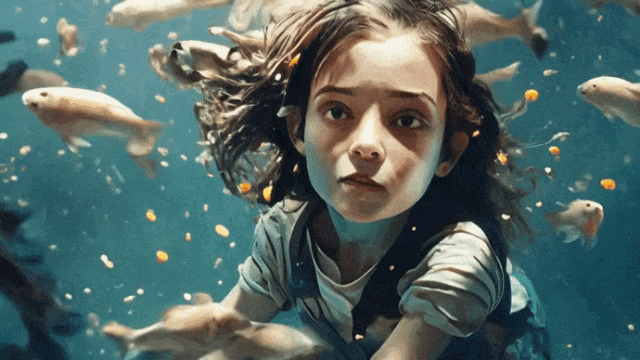
整体来看清晰度、真实性都相当不错,但可能最大的问题仍然在“太短了”,生成的视频仍然像是多张图片的“拼凑”,而似乎没有一个构建统一故事的可能。UniVG 生成效果的整体演示如下面的视频所示:
阿里:I2VGen-XL/EMO
再来看阿里,其实在 Sora 面世前的五个月,阿里就在其魔搭社区上线了视频生成大模型 I2VGen-XL(https://i2vgen-xl.github.io),区别于文字生成视频,阿里 I2VGen-XL 的主要方向是图像生成视频,同样是基于 Latent Diffusion Models(LDM),阿里与腾讯一样也使用的是 U-net 网络,而在模型架构以外,I2VGen-XL 在数据集上也下了功夫,收集了约 3500 万单镜头文本-视频对与 60 亿文本-图像对优化模型。

从视频生成效果来看,I2VGen-XL 也确实对的起“High-Quality”的评价。比如输入一张这样的猫咪图片:

I2VGen-XL 生成的视频效果是这样的:

输入三只狼:

I2VGen-XL 也能让他们“跑起来”:
其实 I2VGen-XL 在问世之初也被冠以“里程碑”的名号,在视频的动作丰富度,还原度,流畅度等等方面也都做到了当时最佳,然而 I2VGen-XL 也仍然只是让图片“动了起来”,也远未达到 Sora “World Simulators”级别的震撼。
除了 I2VGen-XL,也就是在最近几天,阿里又推出了其图片+声音生成视频的 EMO 框架 (Emote Portrait Alive,EMO)。相比 I2VGen-XL,不得不说阿里这个 EMO 要更为好玩一点:

如上图所示,对一张图片任意输入一段音频,就可以让蒙娜丽莎讲话,让赫本开口唱歌:
这里还有一个和 Sora 的小小联动,输入一个 Sora 生成的虚拟决策,再加一段 OpenAI 首席技术官 Mira Murari 接受访谈的音频,就可以惟妙惟肖的以假乱真:
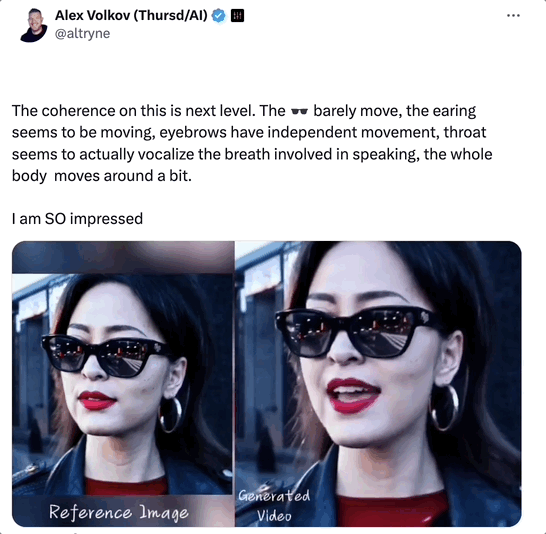
除了单纯的从图像到视频,EMO 更令人惊喜的功能在于无论输入音频的长度如何,EMO 都可以生成相应时长的视频,并且保持角色的个性与特征。而从上面的视频中也可以看到,这次由 EMO 生成的视频超越了之前几家“GIF”的特征,面部表情和头部姿态都可以保持长时间的生动与稳定,也有大佬揪住细节甚至发现 EMO 生成的视频耳朵、眉毛与喉咙的还原度都非常之高:
创业公司:HiDream/PixVerse……
除了这些大厂巨头,国内也有不少创业公司在发力视频生成这一领域,比较有代表的有智象未来(HiDream.ai)的 HiDream 与爱诗科技的 PixVerse。这两款应用都可以方便的在线体验:
HiDream:https://hidreamai.com/ PixVerse:https://app.pixverse.ai/
先来看 HiDream,HiDream 可以直接通过微信进行登录,输入一段文字 HiDream 可以在一两分钟内生成出对应的视频,比如我们以“一只弹吉他的北极熊”进行测试:
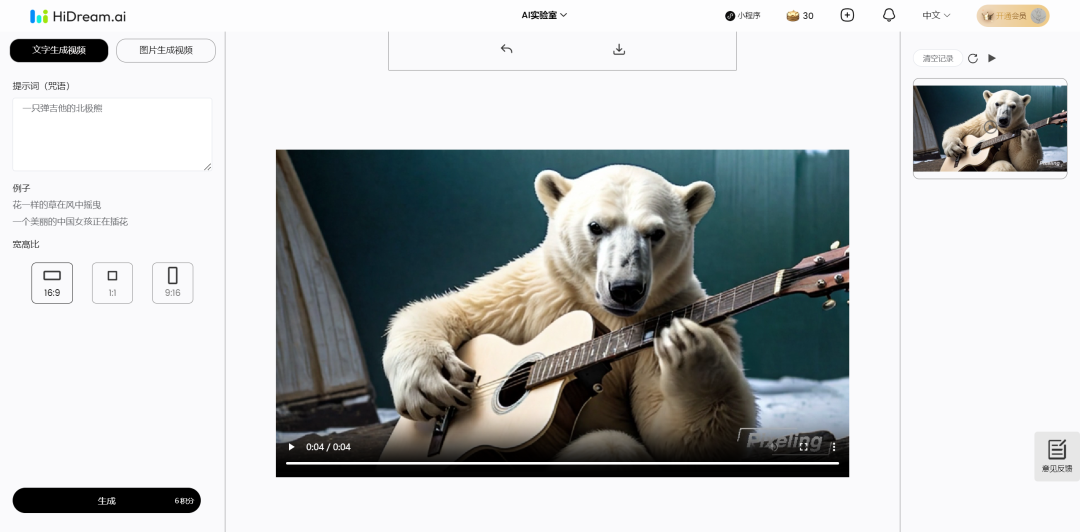
HiDream 可以生成出 4 秒左右的视频,视频清晰度,动作流畅度也都相当不错:

再来看 PixVerse,在输入提示词,选择各种风格之后,PixVerse 在几分钟内也可以生成对应的视频,不过其指令遵循能力似乎并不太能得到信赖,同样以 “一只弹吉他的北极熊” 为输入,当风格勾选“现实”时,PixVerse 生成了一个女生在弹吉他而没有北极熊的影子,而当风格勾选“动画”时,PixVerse 却生成了两只北极熊:
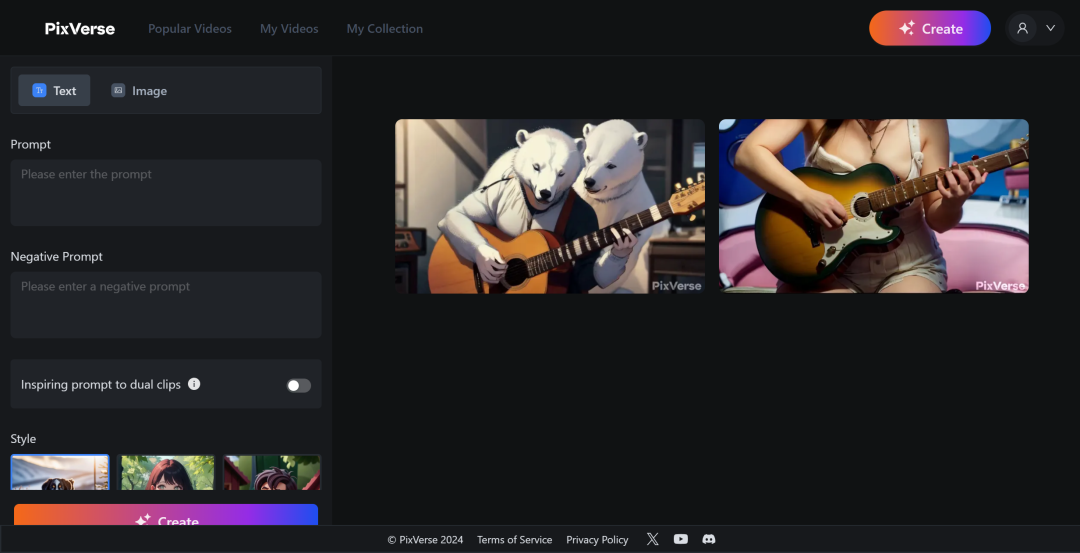
其生成的视频质量如下所示,可以明显看出一些细节的处理仍然不到位:
Sora 之后
放在一个更大的视角,综合来看国产的视频生成模型与 Sora 的对比,尽管这些模型问世时都或多或少的为我们带来了惊喜,在论文与技术报告中宣称超越了各种 benchmark,在没有 Sora 的对比之前,或许我们都可以一个个赞美与表扬过去这里有创新那里有亮点。
但是一旦当我们先行看过 Sora,再去审视这些年龄仅仅比 Sora 大一两月与两三月的模型,我们就会看到其实它们与我们想象中的,也是 OpenAI 带给我们的“真正变革”相距甚远。英国近代史大师艾瑞克·霍布斯鲍姆如此评价工业革命:“一旦工业化进程开始,变革就成为了常态”,而目光转向我们现在经历的这场 AI 革命,我们却总是发现国产模型在“常态的变革”中,完成最多的似乎又总是一些“小修小补”的工作,而一次又一次与里程碑式的进步失之交臂。
在国内一家又一家自诩或被人们称为“中国的 OpenAI”的公司中,在所谓“中美平分 AI 的半壁江山”的论调下,我们似乎总是在进行“赶超战略”,但是就像谷歌在发布它的 Gemini 1.5 Pro 当天 Sora 横空出世那样,如此继续在歌舞升平中“常态化变革”至“长期性平庸”,我们总会一次又一次的看着 ChatGPT、Sora 这样的技术不断重复着他们出现、我们追赶、他们打压、我们落后的循环。
我们需要看到,在我们认为“视频生成最大的挑战在于‘让视频内容动起来’”时,Sora 瞄准的是视频生成背后的“世界模拟器”的功能,我们的视频生成模型与 Sora 的差距可能也不仅仅是我的 4 秒它的 60 秒。也许只有当我们的企业我们的创新不是单单瞄准一个领域圈定的范围画好的边界去集中力量办大事,而是抱着对“智能”而非“智能应用”真正的“好奇”去指导我们想象智能的边界,探索的未知的可能,我们才有可能不再紧随其后,而是弯道超车吧!
原文链接:点击前往 >
文章作者:夕小瑶科技说
版权申明:文章来源于夕小瑶科技说。该文观点仅代表作者本人,扬帆出海平台仅提供信息存储空间服务,不代表扬帆出海官方立场。因本文所引起的纠纷和损失扬帆出海均不承担侵权行为的连带责任,如若转载请联系原文作者。 更多资讯关注扬帆出海官网:https://www.yfchuhai.com/

{{likeNum}}
好文章,需要你的鼓励









 已关注
已关注
 关注
关注
请前往扬帆出海小程序完成个人认证
认证通过后即可申请入驻
咨询/开通企业服务会员
请添加下方商务企业微信
请添加下方商务企业微信

企业服务会员
助力销售转化再上台阶
bd@yfchuhai.com
助力销售转化再上台阶
bd@yfchuhai.com



咨询/开通企业服务会员
请添加下方商务企业微信
请添加下方商务企业微信
企业服务会员
助力销售转化再上台阶
bd@yfchuhai.com
助力销售转化再上台阶
bd@yfchuhai.com
APP
小程序
小程序

微信小程序

扬帆出海APP
微信
公众号
公众号

关注扬帆出海
专注服务互联网出海!
出海人
社群
社群

扫码进群
与10万+出海人同行!

您还未完善信息,请先完善信息在发布
去完善
{{imgUrlTip}}